Matrex 2.1 has been released yesterday.
Version 2.0 was revolutionary because it introduced the concept of client/server; version 2.1 is more an evolution because its purpose is to help the user having full control on projects and on the system.
In detail, these are the big changes:
- The grid/tables have now a real row header, making easier to work with them and giving them a more professional look.
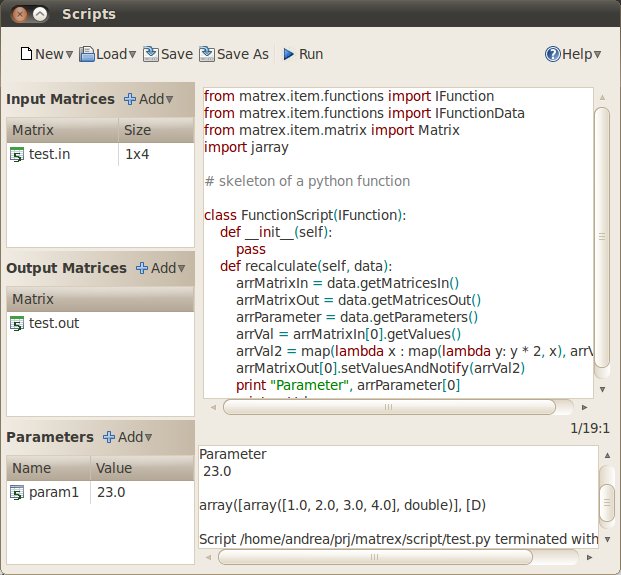
- The script editor, which was very simple, has become a small but complete IDE to write and test scripts. With it the user can write its own functions and can test them before he uses them in his projects.
- For someone that uses Matrex for the first time it is very important to find out immediately how it works. To make it possible, Matrex has now a help button in every window. Here is an example:

The other changes are less visible, but still important:
- Before 2.1 the user could change all the function templates, included the ones that come with the system. Now he can only change templates written by users.
- Fixed permission problems in the installation under Windows, allowing to install under the Program Files directory.
Thanks to Braxton for building the Matrex setup
file for MacOSX. Here is a screenshot of Matrex under MacOSX:

In the next version I will try to change the grid row header buttons under MacOSX to make them rectangular.
Matrex 2.1 is downloadable from here.



{kind=link}